

You may be wondering how a computing device, an online service and other digital services know who you are. Let’s say you provided your details such as an email address or phone number the first time you interacted with an online service. How does the online service know that you’re the same person when you try to use the service the next time? The service can determine who you are using your identity and restrict what you can do using the access control policy. Hence, identity and access management.
Access control, on the other hand, is the enforcement of defined privileges and policies. An access control system could be physical or electronic (digital). A physical access control system is used to enforce access privileges to a physical location. Whereas an electronic access control system restricts access to digital services based on digital identities. This article is focused on identity and access management as it relates to digital services.
Identity and Access Management
Identity and Access Management is the mechanism employed by a system in identifying an entity (a user, device and applications ), ensuring that the user is who it claims to be, and granting that user access to resources based on defined privileges. To simply put it, identity and access management (IAM) identifies a user, validates that user’s identity and then permits access to resources.
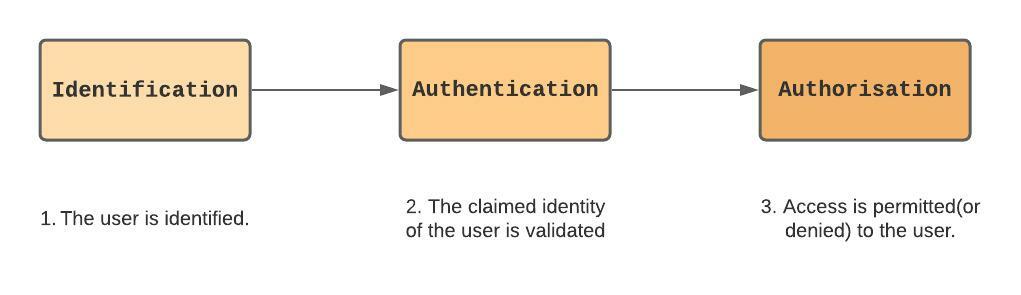
IAM as depicted above starts with identification to authentication and finally authorisation. These 3 components are equally critical. A weakness in any of them will impact the other. For example, if a user is wrongly identified, access could be granted to other users’ resources. In the same way, authentication credentials (such as passwords) could be compromised to steal a user’s identity.
Identification
Digital identity is the unique representation of a user ( person, device, application or service) engaged in an electronic transaction. Hence, Identification is the comparison of a user’s digital identity against many other identities to find a match. In other words, identification is a one-to-many comparison. The identity has to be unique, otherwise, a user cannot be identified from the rest.
A service user identity is usually established at the point of initial use of the service (registration). The established identity is then stored in the service provider’s database so that the service user can be re-identified on subsequent interactions with the service.

On subsequent interaction, the user is identified as follows:
- Who are you? – the identification system requests for the user’s identity).
- I’m Bob – the service user(Bob) provides his identity (e.g. email address, username, phone number etc).
- Does Bob exist? – the identification system checks its database to see if there’s a match with the received identity.
- Yes, Bob does exist – there’s a match with Bob.
The user is said to be identified if there’s a match. Otherwise, the user is not identified.
As you can see, Identification doesn’t necessarily validate and/or guarantee the ownership or trustworthiness of the digital identity. A simple email address may be enough to identify a user for some organisations. Mere entering of the email address doesn’t establish that the user who provided the email address is indeed, the owner. To get some level of assurance as per the owner of the email address, Identity Proofing is required.
Identity Proofing ensures that whoever provided the identity is in possession and control of the identity. Again, that a person verifies an email address or a phone number doesn’t necessarily mean that he/she owns them. It could be that the email address was compromised. SMS interception or SIM swap attack can as well be used to obtain a verification code sent to a phone number. Identity Proofing only provides some level of assurance as to the trustworthiness of the identity in question at the point in time.
For example, an identification document such as a government-issued identity card that requires biometric and/or PIN to prove ownership of the identity card provides a higher level of assurance compared to just confirming an email address.
The level of assurance or confidence in an identity should be determined by an organisation’s business (and/or regulatory) requirements. Hence, the type of identity to request from service users and the identity proofing requirements. See the NIST Identity Proofing and the UK Government Digital Service Guidelines on identity verification for more on identity assurance levels.
That a user is identified successfully doesn’t mean automatic access to resources. Identification is just checking if the user identity does exist. The user still has to prove they’re in control of that identity at that point in time to be allowed access. This brings us to the next component of IAM – Authentication.
Authentication
Authentication is the process of validating that an entity ( a person, device, an application etc) who wants to consume a service is indeed, who their claim to be. Authentication is done using authentication factors (e.g passwords, fingerprint etc). The authentication factor(s) is usually established following the identity proofing process.
The established authentication factors (credentials) are tied to the user’s identity. In this way, the user doesn’t have to undergo the identity proofing process again on subsequent interactions with the service. Rather, the service asks the user to prove ownership of the “claimed identity”.
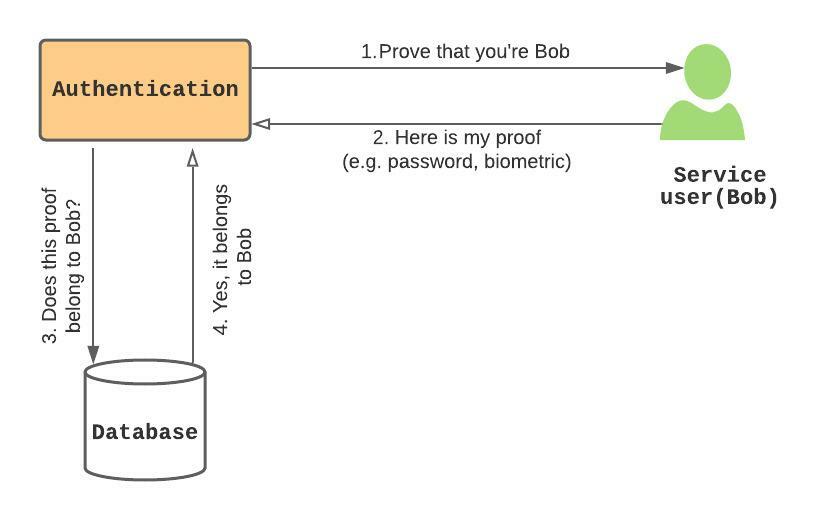
As depicted above:
- Prove that you’re Bob – the authentication system asks the user to prove ownership of the claimed identity (e.g. username, email address etc).
- Here is my proof – Bob provides his authentication credentials (e.g. password, SMS code, OTP etc).
- Does this proof belong to Bob? – the authentication system checks if Bob’s credentials is the same as what he provided. e.g. by comparing the password hash.
- Yes, it belongs to Bob – the stored credential (e.g password hash) matches the received credential.
If the received credential is the same as the stored credential (or a representation of the stored credential), then, the user identity is said to be authenticated. Otherwise, the user is not allowed access.
Again, that a person can provide the correct authentication credential(s) doesn’t mean they own the claimed identity. Authentication credentials can be easily stolen by malicious actors and used for unauthorised access. Authentication only provides some levels of assurance to the service provider as per the authenticity of the user.
As security best practice, the perceived risk (i.e the likelihood that an asset/account could be compromised and the impact to the owner of the asset and/or service provider should it be compromised) should determine the authentication assurance level. The level of assurance should then determine the authentication factors required. See the NIST Digital Identity Guidelines for more on Authenticator Assurance Levels.
Authentication Factors
There are three major authentication factors:
- Knowledge e..g memorised secrets such as a password.
- Possession e.g. a physical authentication device such as a security key and smartphone.
- Inherence e.g. fingerprint and faceprint.
Any of these factors or a combination of them can be used to authenticate a user. When only one factor is used, it’s referred to as “Single” Factor Authentication(SFA). When more than one factor is required, it’s called “Multi-factor” Authentication (MFA).
MFA is recommended unless it’s not practicable. For example, a legacy system that can only accept a password. The reason is that MFA makes it much more difficult for a malicious actor to compromise an account compared to using SFA like password which can be easily compromised using different attack techniques.
Authenticators that involve the manual entry of an authenticator output, such as out-of-band, SMS code and OTPs cannot prevent the service provider from being impersonated. For example, a malicious actor can use a man-in-the-middle attacker to intercept OTP and afterwards, replay it to the service provider. In this type of attack, the malicious actor (rogue server) poses as the service provider to harvest the user credential. This is a result, of manual entry of the authentication credential which does not bind the authenticator output to the specific session being authenticated.
This is why Passwordless MFA is far more secure compared to MFAs that still rely on passwords and One-Time-Passwords (OTP). Don’t be fooled with passwordless experience. There’s a difference between passwordless authentication and passwordless experience. Passwordless experience is just for convenience such as password managers that replays user passwords. A passwordless authentication doesn’t use passwords or OTPs at all in the authentication process. No password is hidden or ever replayed.
Difference between Identification and Authentication
As you have seen, there are clear differences between identification and authentication:
- Identification is a one-to-many comparison whereas authentication (verification) is a one-to-one comparison.
- Identification checks to see if the identity exists in the entire data set. Authentication checks specific attribute of that identity against an already existing attribute in the data set to determine if there’s a match(e.g. comparing the hash of a password).
- Identification determines if a user is known. Authentication determines if the user is authentic.
Authorisation
An authorisation is all about rights enforcement. Authorisation determines what an entity is allowed to do. For example, a privileged user doesn’t have the same access rights as an ordinary service user. Authorisation ensures that an ordinary user doesn’t elevate her privileges to access resources meant for a privileged user.
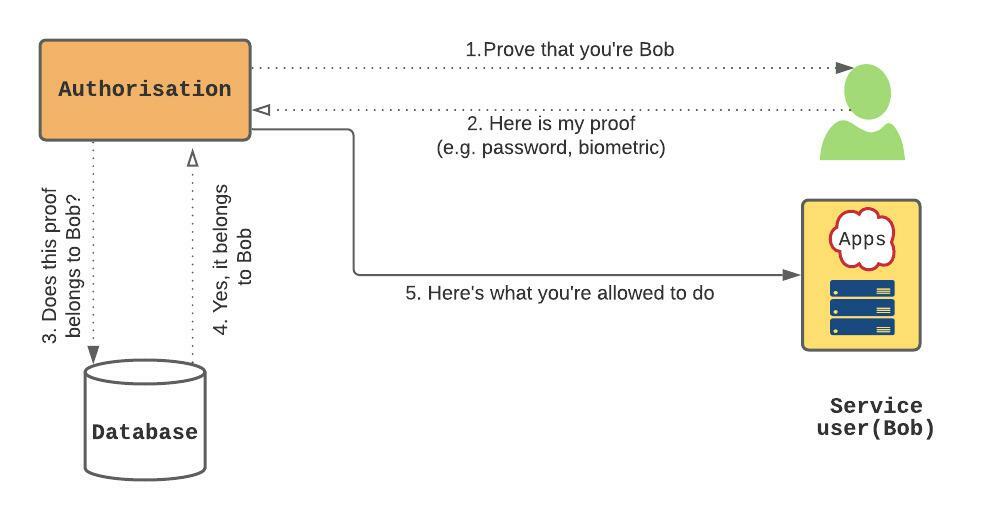
As depicted above, authorisation only permits access based on defined access policies. It only allows the user to access permitted resources and nothing more.
A user may be authenticated but yet, not authorised to access a system. For instance, if an organisation has an access policy that permits access to its sensitive systems only when the access originates from a specific device or a geographical region. In this case, even if an employee’s identity/credential is stolen by a malicious actor. The malicious actor won’t gain access to the sensitive system. In this example, the malicious actor has been authenticated but not authorised as a result of the enforced access policy.
Authorisation ensures that access policies, principles of least privilege, need-to-know, separation duties etc are enforced as required.
Difference between Authentication and Authorisation
By now you must have noticed the difference between authentication and authorisation:
- Authentication determines if a user is authentic (is who the user claims to be). Authorisation determines what a user is allowed to do.
- Authentication checks the validity of identity/credentials. Authorisation checks privileges.
- Authentication is unique to a user and mostly based on knowledge, possession or inherence. Authorisation is based on a system policy.
Despite the difference between authentication and authorisation, neither can exist in isolation. Knowing what a user is permitted to do is not sufficient to grant access. A user has to be authenticated to establish trust in their identity before granting access.
Key Takeaway
Identification, authentication and authorisation are vital to any IAM system. A weakness in any of them is likely going to affect the others.
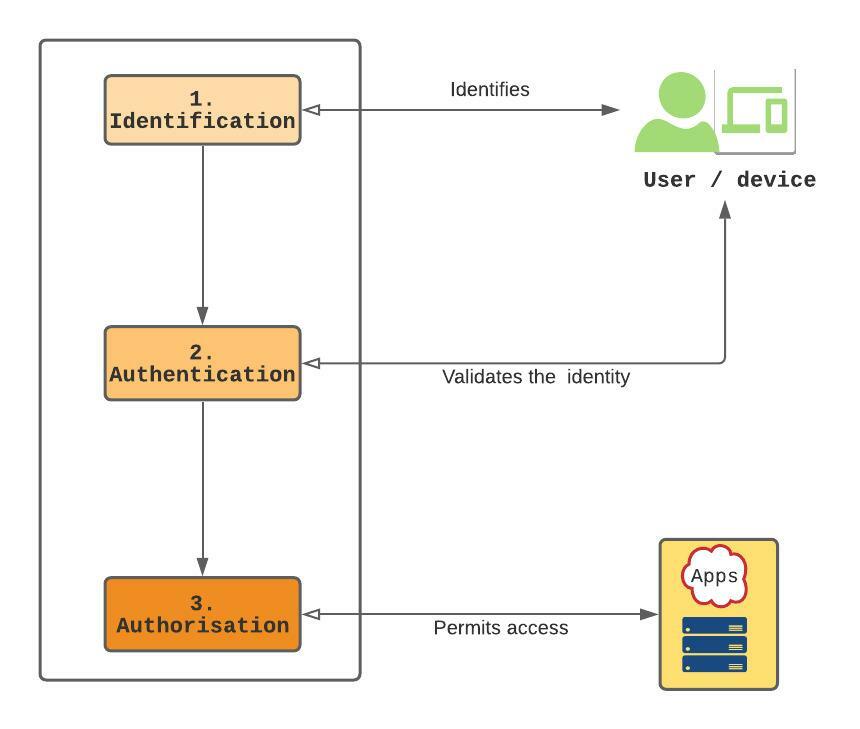
- Identification is a one-to-many comparison. It identifies a user. It doesn’t validate and/or guarantee the ownership or trustworthiness of a digital identity. It only checks if that identity exists. To get some level of assurance as per the ownership of an identity, Identity Proofing is required.
- Authentication validates the claimed identity. That a user can provide the correct authentication credential(s) doesn’t mean they own the claimed identity. Authentication only provides some level of assurance as per the authenticity of the user claiming the ownership of identity.
- Authorisation restricts what an entity can do. It enforces access permissions and privileges.
Conclusion
Organisations should base their IAM requirements on the perceived risks (i.e the likelihood of its assets being compromised and the impact to the organisation should it be compromised). The risk should then guide an organisation in determining the type of identification, identity proofing and authentication assurance level. The level of assurance should then determine the exact authentication credentials to be adopted.